Better Abstractions for the Cloud
 Luke Lombardi
Luke Lombardi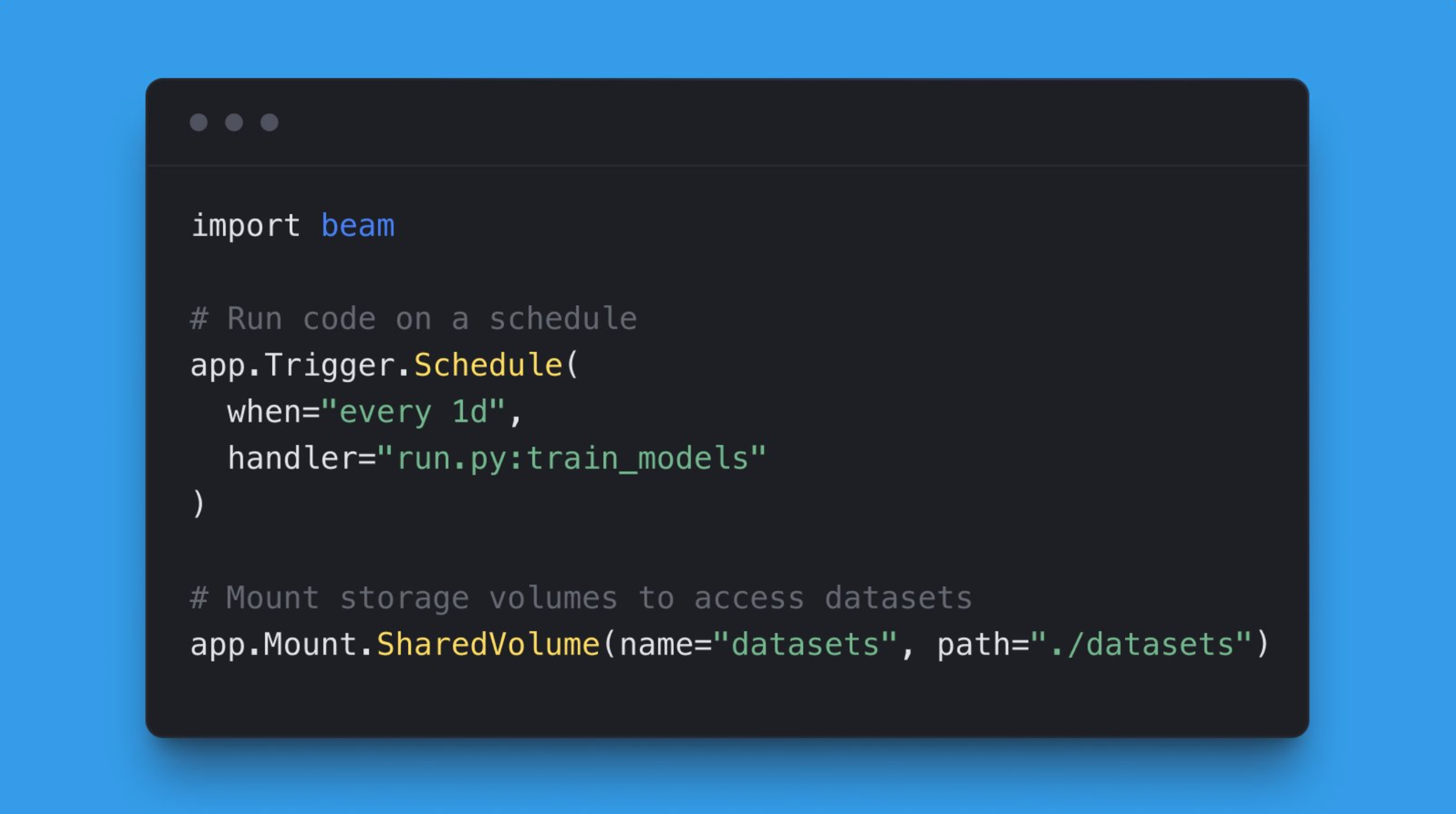
My data pipeline is a mess
In 2017, I was working at a data startup. We had a pipeline that was running on several large EC2 instances, each of which had a bunch of Celery workers eating through a queue of files to process. As a new hire, one of the first issues I encountered was that the workers would crash, or these queues would randomly stop processing. I spent my first couple of weeks ssh’ing into these instances and restarting the workers so tasks could continue processing.
To put this in perspective, I had very little understanding about exactly what the data pipeline was doing. I knew it was taking in a CSV, doing a bunch of processing with numpy, and dumping the results into a database. The project was a giant monolithic mess. But I was tired of dealing with those servers.
Discovering serverless
I don’t remember exactly how I stumbled upon AWS Lambda. But as soon as I did, I knew I wanted to jam my data pipeline into a Lambda function. Using Lambda functions, I could process each CSV as a separate python function invocation, with no servers to manage. This sounded great on paper - so I set to work. I laid out the tasks in front of me:
- Take a giant repo, which I didn’t fully understand, and refactor it to run in my Lambda function
- Install Python requirements in my Lambda environment
- Figure out some way of queueing incoming tasks, and managing retries and failures
Soon after I started working, I realized serverless had drawbacks. At that time, Lambda had timeouts that were slightly lower than how long it took the average task to process. Requirements were annoying to install. And refactoring our code to fit in a Lambda “handler” wasn’t straightforward.
After soldiering on for a week, I managed to set up a few things: an SQS queue, a retry mechanism, and an API gateway to enqueue tasks into that SQS queue. I got my Lambda function to run under the 5 minute limit (the timeout is much higher now, but at the time this required a little finagling). I demoed the new system to my boss, who was thrilled. We no longer had to manage the infrastructure and could spend our time thinking about the pipeline code. We shut off the EC2 instances and we went on with our lives. The end.
Just kidding, it’s still broken
After we got this system in production, we started to run into trouble. It turned out we were collecting a lot more data than we had expected, and so those files were taking much longer to process than the averages I had tested with. My functions were timing out. Back to the drawing board. I had to figure out a way to split up the files into chunks, which ended up being much more complicated than it sounds.
Testing was a nightmare. There were frameworks for managing my functions, like serverless and SAM, but neither of them really solved my problem. I wanted a testing environment that looked just like production, timeouts and all. I ended up hacking together a bunch of custom tools as a test harness, which allowed me to simulate most of the stuff I wanted to simulate – but it still wasn’t quite like my production environment. Mocking out a bunch of interacting services (SQS/API Gateway/Lambda/S3) was a huge pain in the ass.
Eventually, I managed to fix our pipeline issues, and I moved onto other projects.
Wouldn’t it be nice if all of these services were abstracted for you?
It’s worth noting that our company didn’t care at all about the cost savings we were gaining from AWS Lambda. They just wanted a system that wasn’t brittle and was easy to maintain. I think this is a key misconception people have when they approach serverless. Serverless can save you money, but in my experience its main benefit is reducing the overall complexity of your system. At its core, serverless allows engineers to think about other things besides infrastructure.
We ended up eventually moving off of Lambda and onto ECS (Elastic Container Service). It didn’t have time constraints and still took care of the underlying servers (at least for the most part. ECS forces you to configure a bunch of stuff, but you don’t have to manage your own cluster).
Where serverless falls short
The core premise of serverless is enticing. Define a function in your language of choice (Python, Go, NodeJS), and get a lightweight runtime where your code can run without you having to think too much about how it works. It doesn’t matter if you’re using AWS Lambda, Google Cloud functions, or Azure functions – they all do roughly the same thing, and they’re all great products.
But serverless functions don’t exist in a silo. Serverless frameworks build dependencies on other cloud services, which perform some ancillary functions your code needs to run.
If you start using AWS Lambda, chances are you’re also going to need several additional AWS services: SQS (queue), RDS (database), S3 (storage), and API gateway (routing). Before you know it, your lightweight serverless project has forced you to become an AWS IAM expert.
If you’re an engineer using a serverless framework, you’re probably going to need to get familiar with the rest of the cloud as you go. And because of the challenges replicating a serverless function locally, you’re going to have a hard time iterating as you work.
For all its benefits, serverless doesn’t take enough weight off our shoulders. We can do better.
We build the same stuff over and over
After a few years of software engineering, you see the same patterns over and over again.
Take the example above. I wanted to build a data pipeline based on a task queue, so I set it up with AWS, Lambda, and SQS. If I wanted the same thing to run on a schedule, I’d use AWS, Lambda, and Cloudwatch events. And if I wanted it to behave like a REST API, I’d put an API Gateway in front of it. If we take a step back and consider each of these as general architecture patterns, they’d fall into three categories:
- Task Queue
- Scheduled job
- Synchronous/Rest API
And this is just to name a few.
As developers, we often think our problems are special. And sometimes, there are justifications for this. Maybe your team doesn’t trust you to hire an external vendor to own mission-critical parts of your infrastructure. Maybe you just want to build a complex system. These arguments can have merit. But building your own systems takes away time and resources that could be better spent figuring out what your product really needs in order to make users happy.
If we focused more on business logic and less on system design, we’d ship software a lot faster.
Accessing common infra patterns with Python
Cloud services aren’t supposed to add complexity to our lives – they’re supposed to remove it. In a perfect world, the cloud would be designed to quickly iterate on business logic, rather than forcing us to string together blocks of glue code.
Simple cloud abstractions exist at larger companies. Companies like Dropbox have dedicated engineering teams who set up internal services that allow their engineers to quickly spin up task queues, one time jobs, or develop on remote hardware.
But what about the rest of us? We need a cloud that operates like a high level protocol. We need a cloud that configures itself for you. We need a cloud that lets us ship products to users faster.
For example, let’s say we want a task queue. Instead of a hodge-podge of AWS services, what if it looked like this?
Here’s what this code would do:
- Set up a distributed queue for you
- Create an API to accept workloads / enqueue things for processing
- Run those workloads in serverless containers with the exact compute requirements you’ve asked for
This means you wouldn’t have to set up a database, a queue, or a web endpoint. It’s all managed for you – you don’t even need an AWS account!
At Beam, we build abstractions on top of the cloud. Right now, we have a couple that we’re testing out. They aren’t perfect. But the goal is to build systems that make engineers work faster, and stop repeating themselves.



